Getting Started with gcamfaostat
2025-01-12
Source:vignettes/vignette_getting_started.Rmd
vignette_getting_started.RmdIntroduction
Global economic and multisector dynamic models have become pivotal
tools for investigating complex interactions between human activities
and the environment, as evident in recent research (Doelman et al. 2022; Fujimori et al. 2022; IPCC 2022;
Ven et al. 2023). Agriculture and land use (AgLU) plays a
critical role in these models, particularly when used to address key
agroeconomic questions (Graham et al. 2023;
Yarlagadda et al. 2023; Zhang et al. 2023; Zhao, Calvin, Wise, Patel, et
al. 2021; Zhao, Calvin, and Wise 2020). Sound economic modeling
hinges significantly upon the accessibility and quality of data (Bruckner et al. 2019; Calvin et al. 2022; Chepeliev
2022). The Food and Agriculture Organization Statistis (FAOSTAT)
(FAO 2023) serves as one of the key global
data sources, offering open-access data on country-level agricultural
production, land use, trade, food consumption, nutrient content, prices,
and more. However, the raw data from FAOSTAT requires cleaning,
balancing, and synthesis, involving assumptions such as interpolation
and mapping, which can introduce uncertainties. In addition, some of the
core datasets reported by FAOSTAT, such as FAO’s Food Balance Sheets
(FBS), are compiled at a specific level of aggregation, combining
together primary and processed commodities (e.g., wheat and flour),
which creates additional data processing challenges for the agroeconomic
modeling community (Chepeliev 2022). It is
noteworthy that each agroeconomic modeling team typically develops its
own assumptions and methods to prepare and process FAOSTAT data (Bond-Lamberty et al. 2019). While largely
overlooked, the uncertainty in the base data calibration approach likely
contribute to the disparities in model outcomes (Lampe et al. 2014; Zhao, Calvin, Wise, and Iyer
2021). Hence, our motivation is to create an open-source tool
(gcamfaostat) for the preparation,
processing, and synthesis of FAOSTAT data for global agroeconomic
modeling. The tool can also be valuable to a broader range of users
interested in understanding global agriculture trends and dynamics, as
it provides accessible and processed data and visualization
functions.
The gaps gcamfaostat fills
Figure 1 shows a standard framework of using FAOSTAT data in GCAM. GCAM is a widely recognized global economic and multisector dynamic model complemented by the gcamdata R package, which serves as its data processing system. Particularly, gcamdata includes modules (data processing chunks) and functions to convert raw data inputs into hundreds of XML input files used by GCAM (Bond-Lamberty et al. 2019). As an illustration, in the latest GCAM version, GCAM v7 (Bond-Lamberty et al. 2023), about 280 XML files, with a combined size of 4.1 GB, are generated. Although AgLU-related XMLs represent only about 10% of the total number of files, they contribute over 50% in size (~2.1 GB). The majority of AgLU-related data, whether directly or indirectly, rely on raw data sourced from the FAOSTAT.
Nonetheless, the FAOSTAT data employed within gcamdata has
traditionally involved manual downloads and may have undergone
preprocessing. In light of the increasing data needs, maintaining the
FAOSTAT data processing tasks in gcamdata has become increasingly
challenging. In addition, the processing of FAOSTAT data in the AgLU
modules of gcamdata is tailored specifically for GCAM. Consequently, the
integration of FAOSTAT data updates has proven to be a non-trivial task,
and the data processed by the AgLU module has limited applicability in
other modeling contexts (Zhao and Wise
2023). The gcamfaostat package aims
to address these limitations (Figure
2). The targeted approach incorporates data preparation,
processing, and synthesis capabilities within a dedicated package,
gcamfaostat, while regional and sectoral aggregation functions in the
model data system are implemented using standalone routines within the
gcamdata package. This strategy not only ensures the streamlined
operation of gcamfaostat but also
contributes to keeping model data system lightweight and more
straightforward to maintain.
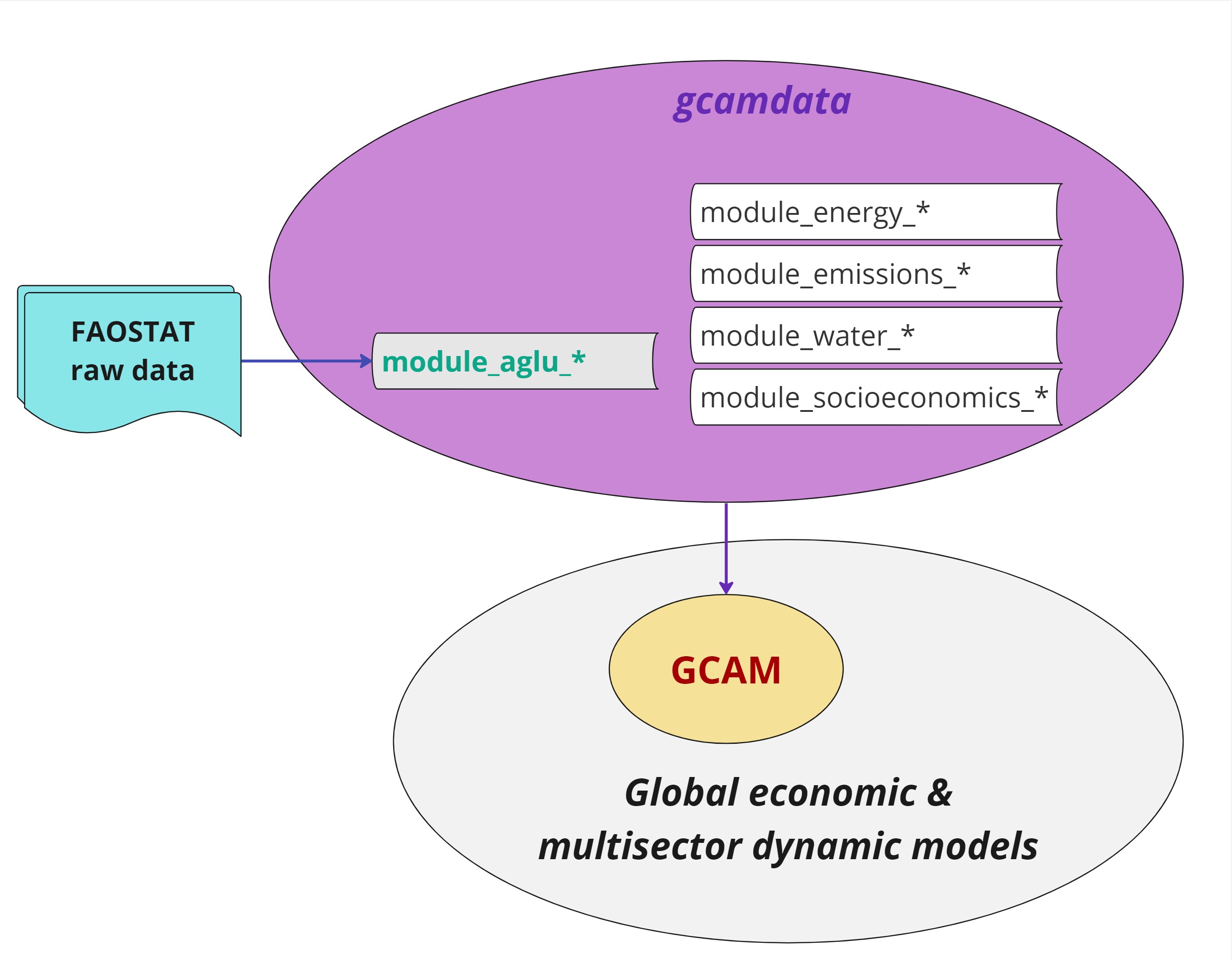
Figure 1. The original framework of utilizing FAOSTAT data in GCAM and similar large-scale models. Note that FAOSTAT data is mainly processed in the AgLU modules in gcamdata while there could be interdependency across data processing modules.
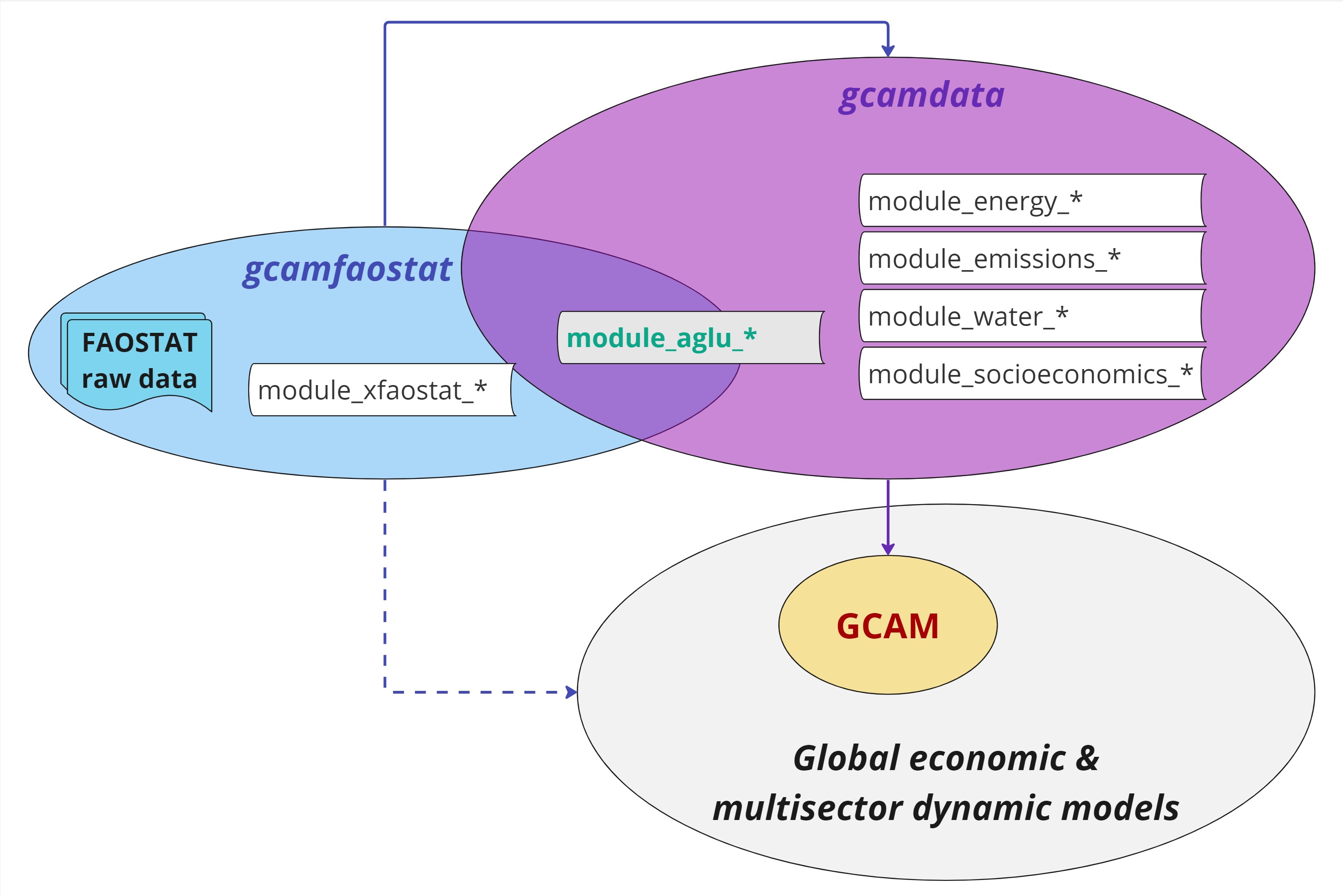
Figure 2. The new framework of utilizing FAOSTAT data in GCAM and similar large-scale models through gcamfaostat. Modules with identifier xfaostat only exist in gcamfaostat. The AgLU-related modules (aglu) that rely on outputs from gcamfaostat can run in both packages. Other gcamdata modules that process data in such areas as energy, emissions, water, and socioeconomics only exist in gcamdata.
Installing gcamfaostat
Clone this repository (size < 1 GB)
- On the command line: navigate to your desired folder location and then enter
- Or using
devtoolsto download and install in r environment (into.libPaths())
install.packages("devtools") # install devtools package if not already
devtools::install_github("jgcri/gcamfaostat")- Note that
gcamfaostatis not dependent on GCAM, so it can be installed to folders as desired by the user.
Loading the gcamfaostat package
- Open the
gcamfaostatfolder you just cloned and double-click thegcamfaostat.Rprojfile. RStudio should open the project. - Then to load the
gcamfaostatpackage:
devtools::load_all()Package dependencies
Users can consider using renv.
-
renvhas been initialized and arenv.lockfile was included. - Using
renvwill save a private R library with the correct versions of any package dependencies. - Please find more details here
in
gcamdatamanual.
Run the driver
driver_drake and driver
Users should now be ready to run the driver, which is the main
processing function that generates intermediate data outputs and final
output (csv or other files) for GCAM
(gcamdata) or other models. Driver functions will run data
processing modules/functions sequentially, see Processing
Flow. There are two ways to run the driver, both inherited from
gcamdata.
driver_drake() runs the driver and stores the outputs in
a hidden cache. When you run driver_drake() again it will
skip steps that are up-to-date. This is useful if you will be adjusting
the data inputs and code and running the data system multiple times. For
this reason, we almost always recommend using
driver_drake(). More details can be found in the here.
See here for more options when running the driver, such as what outputs to generate or when to stop.
For gcamfaostat, it is recommended to use
driver_drake() so the data tracing and exploring after the
drive will be possible, even though it may take longer to run and
additional space (for drake cache) compared to driver().
The driver() approach has a default option
(write_outputs = T) to write the intermediate
csv outputs to ./outputs.
Output files
- In
constants.R, users can setOUTPUT_Export_CSV == TRUEand specify the output directory (DIR_OUTPUT_CSV) to export and store the output csv files. - The default directory is
outputs/gcamfaostat_csv_output. - Users can also make use of the functions to trace the processing by
step, when
driver_drake()is employed.