User Guide
This page gives details on model settings.
Workflow Overview
The core workflow of GLORY consists of 2 stages: linear programming and supply curve construction.
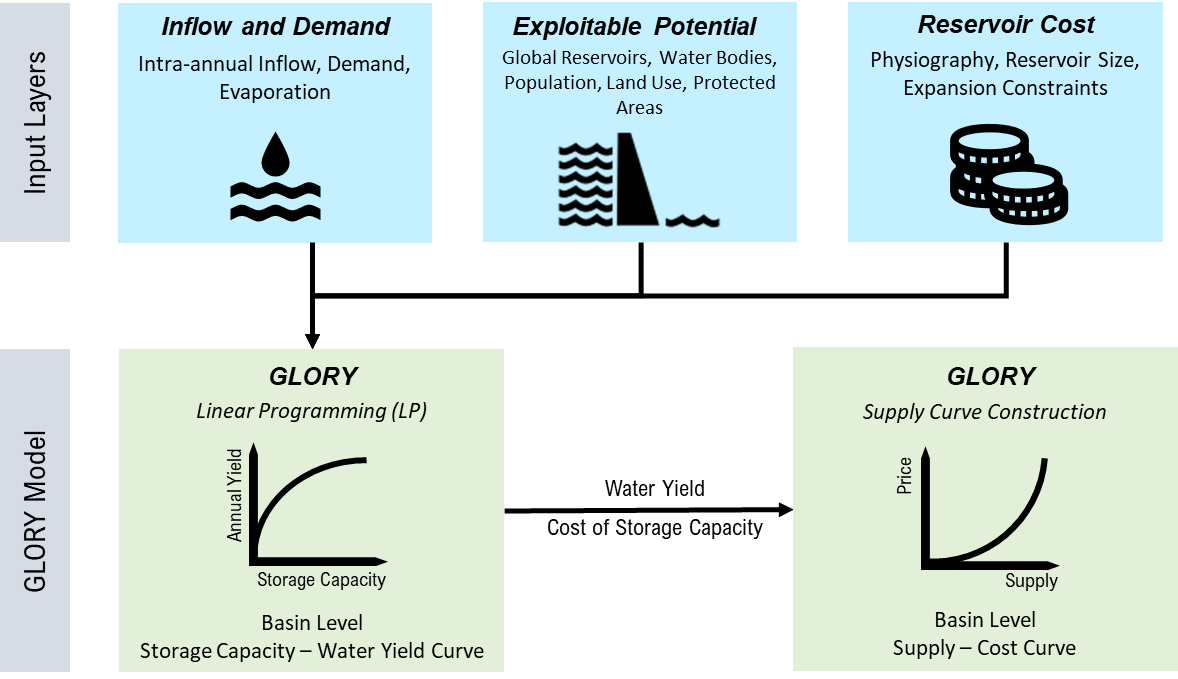
Figure 1. GLORY framework for required input data and model structure.
Global River Basins
The default GLORY model is operating for each of the 235 global river basins shown in Figure 2 below. Details on basin names and the corresponding basin ID can be found using GLORY functions.
import glory
config = glory.ConfigReader(config_file='path/to/config/file')
# use any basin_id and period
data = glory.DataLoader(config=config,
basin_id=83,
period=2025)
# check the basin ID and basin names for global 235 basins
data.basin_name_std
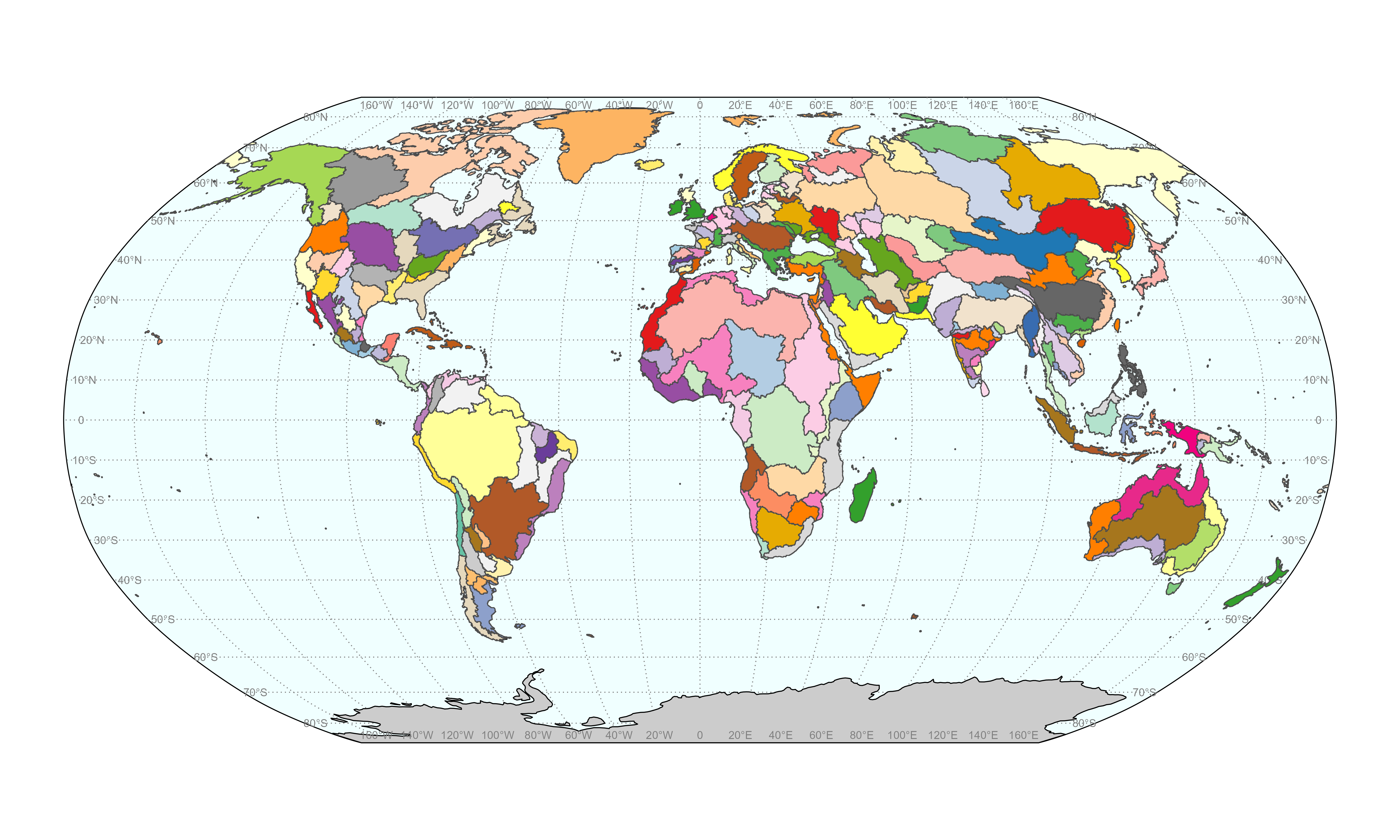
Figure 2. Global 235 HUC2 basins identified by GLORY.
Reservoir Storage Capacity and Water Yield Relationships
Reservoir annual water yield is defined as the annual volumetric quantity of water that can be released from a reservoir for downstream uses within a year. Water yield can be estimated based on a given volume of reservoir storage capacity. By estimating yields at different storage capacity level, we can obtain the capacity-yield curve. With changing patterns of intra-annual climate and demand, a reservoir with the same storage capacity can yield different amount of water annually. GLORY is developed to capture such variations. Figure 3 shows an example of capacity-yield curve.
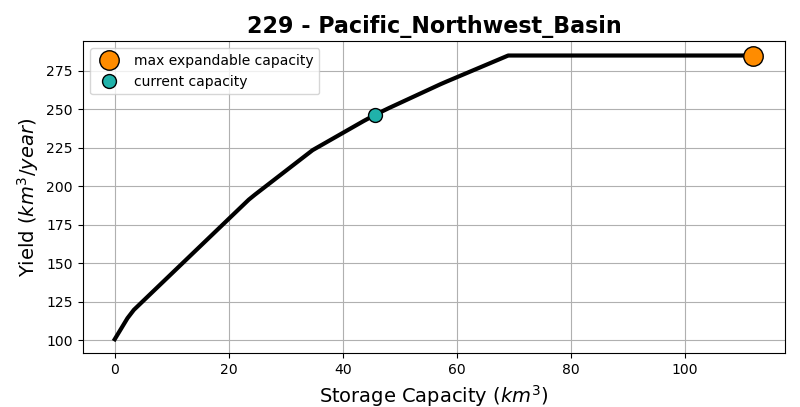
Figure 3. Example of a capacity-yield curve.
Configuration File
The configuration file uses YAML structure to set up options for running GLORY. The options in this file correspond to the arguments passed to the GLORY class. Options not present in the configuration file will use the default. An overview is provided in the following table, with more details and examples below.
More details of the structure of the files or options can be found in each subsection.
Option
Description
root
Root directory for inputs and outputs
Relative file path for each input file, including climate, sectoral_demand, monthly_profile, slope, and reservoir
Relative file path for each reference file
Choice of basin ID, GCAM period, and base year period
Initial number of breakout segments on a capacity-yield curve. Default is 100
Choice of linear programming model solver. Default is glpk
Choice of types of outputs to generate
input_files
The input data are pre-processed data for GLORY based on various dataset including hydrology, water demand, GranD, hydroLAKES, land use land cover, population, protected areas, and slope. The followings describes the structure of the input data.
Below is an example configuration for the input files.
input_files:
climate: inputs/climate_canesm5_r1i1p1f1_ssp126_2020_2050.csv
sectoral_demand: inputs/demand_hist.csv
monthly_profile: inputs/fraction_profile_canesm5_r1i1p1f1_ssp126_2020_2050.csv
slope: inputs/slope.csv
reservoir: inputs/reservoir.csv
Note
To update the data, please follow the same data format and structure for each input file.
climate
Variable Name
Description
Unit
basin_id
Basin ID
-
basin_name
Basin name
-
period
Period for a range of years. E.g., period 2025 is a 5-year period of 2021-2025
-
runoff_km3
Average annual basin runoff over the period
km3/year
evaporation_km
Average annual evaporation depth from reservoir surface over the period for the basin
km/year
sectoral_demand
Variable Name
Description
Unit
basin_id
Basin ID
-
basin_name
Basin name
-
sector
Demand sectors, including domestic, electric, industry, irrigation, livestock, and mining
-
demand_km3
The historical average annual water demand from the sector
km3/year
monthly_profile
Variable Name
Description
Unit
basin_id
Basin ID
-
basin_name
Basin Name
-
period
Period for a range of years. E.g., period 2025 is a 5-year period of 2021-2025
-
month
Month number. E.g., 1, 2, …, 12
-
inflow
Monthly profile of average inflow over the period to the reservoirs within the basin
-
evaporation
Monthly profile of average evaporation over the period from water surface to the reservoirs within the basin
-
domestic
Monthly profile of average domestic water demand over the period within the basin
-
electric
Monthly profile of average electricity water demand over the period within the basin
-
industry
Monthly profile of average industrial water demand over the period within the basin
-
irrigation
Monthly profile of average irrigation water demand over the period within the basin
-
livestock
Monthly profile of average livestock water demand over the period within the basin
-
mining
Monthly profile of average mining water demand over the period within the basin
-
slope
Variable Name
Description
Unit
basin_id
Basin ID
-
basin_name
Basin name
-
slope
Average basin slope
-
reservoir
Variable Name
Description
Unit
basin_id
Basin ID
-
basin_name
Basin name
-
mean_cap_km3
Average basin reservoir storage capacity
km3
nonhydro_cap_km3
Total storage capacity for non hydropower reservoirs
km3
nonhydro_area_km2
Total surface area for non hydropower reservoirs
km2
expan_cap_km3
Expandable/exploitable basin storage capacity potential
km3
b
Parameter b in the area-volume relationship V=cA^b for basin reservoirs
-
c
Parameter c in the area-volume relationship V=cA^b for basin reservoirs
-
reference_files
Reference files are for mapping basin to different spatial scales. The reference files includes basin to country mapping and basin to region mapping. Below is an example configuration for the reference files.
reference_files:
basin_to_country_mapping: inputs/basin_to_country_mapping.csv
basin_to_region_mapping: inputs/basin_to_region_mapping.csv
basin_to_country_mapping
This is a default mapping file from gcamdata system.
Variable Name
Description
GCAM_basin_ID
Basin ID from 1 to 235
Basin_long_name
Basin name with underscores. For example, Arctic_Ocean_Islands
GLU_name
Basin name in GCAM’s Geographic Land Unit (GLU) format. For example, Arctic_Ocean_Islands’s GLU name is ArcticIsl
basin_to_region_mapping
Variable Name
Description
region
Region name
gcam_basin_name
GCAM basin name in Geographic Land Unit (GLU) format
scales
Under the “scales” section, you can select the basins and time steps to include in the model. Below is an example configuration for the scales.
scales:
basin_id: [167, 168] # use 'all' to select all basins. Use comma separated list to select multiple basins
gcam_period: [2025] # 5-year interval periods that >= base period. Use comma separated list to select multiple time steps
base_period: 2020 # first future period. In current GCAM, 2020 is the default fist future period
Note
Running all 235 basins will take a while. We recommend to start with one or two basins for testing.
parameters
The init_segments parameter determines the initial number of segments on a capacity-yield curve, impacting how many points the LP model needs to solve on the capacity-year curve. Increasing the number of segments can enhance the curve’s resolution and accuracy, while a lower number of segments may reduce precision. The default value is 100. Below is an example configuration for the parameters.
parameters:
init_segments: 100
lp
The linear programming model solver used in the GLORY model. The default and recommended solver is glpk. Other solvers might be available.
lp:
solver: 'glpk'
outputs
Configure the output directory and specify the data to be generated. Set to True to enable the output for each data item. Below is an example configuration for the outputs setup.
outputs:
output_folder: outputs # relative path to the outputs folder
capacity_yield: True # capacity-yield curve at the basin level
supply_curve: True # supply curve at the basin level
lp_solution: True # the water balance solution at each storage capacity point
diagnostics: True # diagnostic figures